
What is a Container?
Exploring the unique features of the Linux system that provide the ability to run re-usable containerized applications


To properly use and secure containerized applications understanding the software components that ultimately create a container is essential. You can't defend what you don't understand, and containers are quite different from traditional deployment environments. By answering a few key questions we can begin to understand the advantages and disadvantages of using containers, as well as gaining a finer perspective on Linux software in general.
What components of Linux allow a container to be "contained"? Are they isolated from the rest of the system? How can this isolation be broken? Which attack vectors do containers share with traditional applications and do there exist attack vectors that are exclusive to containers?
CONTAINERS vs. VIRTUAL MACHINES
Analogy is a powerful technique, and many try to introduce the concept of a container as being analogous to a virtual machine. This may be helpful in the beginning but once you start to learn what a container is this analogy is only limiting and only leads to confusion, which is why it shouldn't have been used in the first place.
If containers were miniature virtual machines they would be called "mini-vms" and not "containers". The differences between containers and virtual machines are numerous, and the only real similarity that they have is that they have a filesystem that is either independent or pseudo-independent from that of the host operating system.
One of the key differences between containers and virtual machines is their implementation of the Kernel. You've probably heard of the Kernel but in case you haven't it is the brain of the computer, it is the operating system itself. Every time you do something on your computer in the user space it will take that command and send it to the Kernel where various permission checks and other types of work are done. The end user mostly doesn't have to worry about the Kernel and it is abstracted away.
Anyway, virtual machines run on what is called a hypervisor. The hypervisor has a kernel of its own with a virtual machine's kernel running on top of it. Every time the kernel of the virtual machine needs to do something it will translate those calls into something that the hypervisor can understand. Whilst a container is just another Linux process making syscalls to the kernel, granted a few more things go into isolating it from other processes we'll touch on those later. Essentially the point you should take away is that virtual machines have an entirely separate kernel from that of the host they are running on.
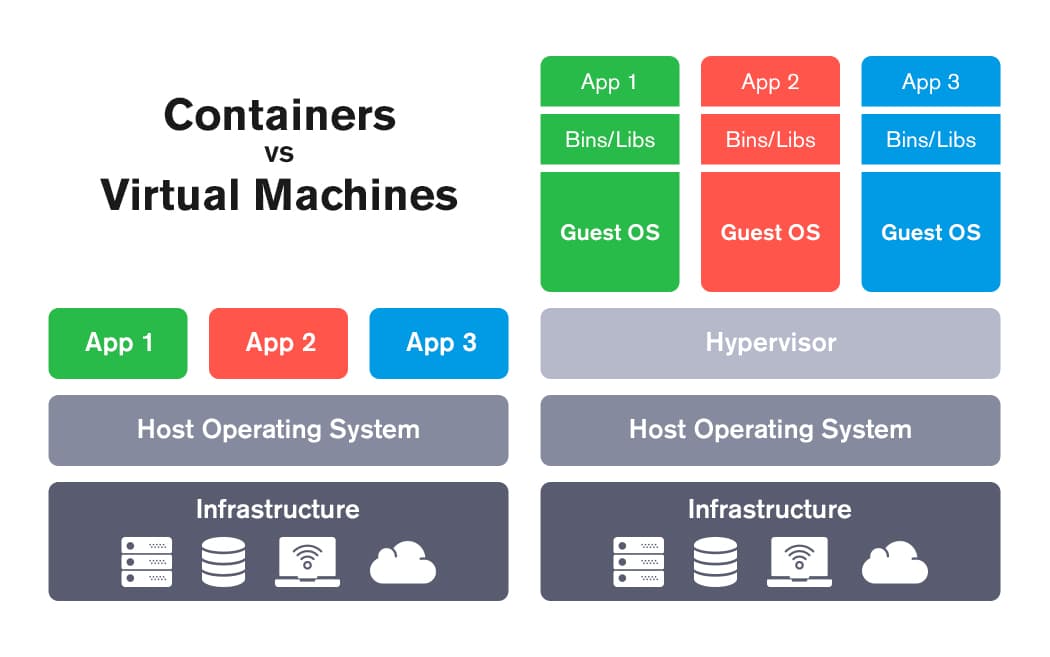
The fact that containers share a kernel with their host provides advantages in speed in terms of getting the container up and running. A virtual machine might take up to a few minutes to spawn, whilst a container only takes a few seconds. Containers also take up less computational resources than virtual machines, at the end of the day the container is a special type of process that is meant to specialize in doing one thing. If I choose to run a web server on a virtual machine I'm going to be using and therefore paying for all of the non-webserver things that the virtual machine is using.
Although virtual machines are slower and less computationally efficient than containers they do offer more isolation just by nature of having a kernel that is separate from that of the host hypervisor and the other VMs that may be running on it. Containers are considered to be "lightweight" relative to virtual machines, which is exactly why they are being used. Containers offer the ability to quickly and cost-effectively scale infrastructure to adjust to user demands in real-time.
CONTAINER ISOLATION
Now that we have a rough understanding of the differences, as well as the advantages and disadvantages in terms of speed, computation and isolation provided by containers and virtual machines it's time to start focusing on figuring out what the heck a container is.
Several components orchestrate the existence of containers and ultimately provide pseudo-isolation from other processes. We'll cover each of these in detail in later sections, for now, we're just going to glance at each of them.
Namespaces are tags assigned to processes (remember a container is just another process) that control which resources the process can "see" or interact with. Altogether there are 6 different namespace types and each process will belong to exactly one instance of each type.
Cgroups or control groups are pseudo-filesystems that set limits on the computational resources like memory, I/O etc. that a process can use. If a process exceeds the limits placed on it by the Cgroup it will be killed.
Capabilities are permission checks for the kernel. If a container could make any system call to the Kernel it wouldn't be that isolated, it would have free reign over the entire system. Capabilities are much more complex than traditional Unix file permissions and often enough containers need to have their capabilities set manually to have proper isolation.
Lastly, there is the Union File System which in combination with the
chrootcommand creates the illusion of a filesystem that is separate from that of the host filesystem. The union file system also provides speed and efficiency in container image builds. By layering filesystems on top of one another and gluing them together the UFS allows different containers to re-use various components of a filesystem as needed.
Now it's time to get our hands dirty.
NAMESPACES
According to an ancient legend, a Linux process is "something running on the computer". Although this is a rather platonic explanation it captures what a process is quite accurately. A process can be anything from running a binary from /bin or a daemon running in the background. The Linux system tracks processes by attaching a numerical process ID to each and storing other relevant process data within the /proc directory.
The first process on a Linux system is systemd, it sets up the system by spawning and managing other core processes. You can view all of the processes on your system by running ps -axjf. This command will organize the processes in a hierarchy with systemd at the top and all of its subprocesses, including your terminal shell(s) beneath it.
On a side note, the tree-like pattern provided by ps -axjf is a self-similar fractal pattern that is ubiquitous in the natural world, for example, the same pattern appears in our peripheral nervous system and on the branches of a tree. Computers are nature and nature is beautiful!
Every process will belong to a set of namespaces. According to the official Linux Programmers Manual, a namespace:
"wraps a global system resource in an abstraction that makes it appear
to the processes within that namespace that they have their isolated
instance of the global resource. Changes to the global resource are
visible to other processes that are members of that namespace, but are
invisible to other processes... "
Essentially Namespaces are responsible for isolating the resources that a process can "see" and thus interact with. There are 8 different namespaces each of which is responsible for isolating a different type of resource. Here is a list of the namespaces and the resources they are responsible for:
"Cgroups -> Isolate /cgroup directory, cgroups control computational resources"
"IPC (Inter process communication) -> Isolate System V IPC, POSIX message queses"
"Network -> Unironically isolates network devices, stacks, ports etc."
"Mount -> Mount Points:"
"PID -> Process Ids"
"Time -> Boot and monotonic clocks"
"User -> User and Group Id's"
"UTS -> Hostname and NIS domain name"
According to Liz Rice's book Container Security, highly recommended,
"A process is always in exactly one namespace of each type.
When you start a Linux system it has a single namespace of each type,
but as you'll see you can create additional namespaces and assign
processes to them. "
This was a bit confusing to me at first but I think of namespaces in the same way as an Object in OOP languages. Each of the six different namespaces is like a different class. There can be multiple instances of each namespace class and a process will belong to a single instance of each of the 8 different namespace classes.
For example, there would be an instance of the host user namespace that starts upon system boot and holds all the regular users and groups, but there would also be separate instances of the user namespace type for each running container. This is ultimately what separates the users and groups of containers A, B etc. from each other and the host system.
There is an entire Kernel API that is used to work with namespaces, create new ones, tear them down and assign processes to them. But, for now, all you need to take away is that there are 8 different types of namespaces. A Process belongs to exactly one instance of each type and namespaces are ultimately responsible for isolating the various resources that are available to a process.
CGROUPS
The Linux system has a finite amount of computational resources such as memory, I/O, device access and the networking stack which it must manage. To make sure that one process doesn't eat up to much computational power it sets limits on the process by assigning it to a group ie. a control group. Whenever a process is spawned it will be assigned to a cgroup by the kernel through the /sys/fs/cgroup directory, all of the processes children will belong to the same cgroup unless otherwise specified.
Limiting computational resources will prevent a container, or any other process from becoming a cancer and starving all of the other processes from the resources that they need. So what happens when a process exceeds the limits defined by its cgroup? It will be killed automatically by the Kernel. Cgroups act as a police force keeping processes in line and ensuring that no process "steals" more resources than it needs.
CAPABILITIES
Standard Linux file permissions are much simpler than those of the Windows operating system. It's as simple as assigning read, write, or execute file permissions for the owner, groups and other users on the system. There are some exceptions to this rule like the suid bit, which also plays an important role in container security but we're going to dive into that in another post.
99% of what we do on a Linux system occurs in the user space which abstracts a lot of the magic from the end user for both simplicity and convenience. Beneath the user space is the Kernel, which is the brain of the system. It technically is the operating system.
When something happens in the userspace a series of user-space file permission checks will occur. At the end of the day, everything goes to the kernel, and there are a series of permission checks known as capabilities that manage system calls ie. calling functions provided by the kernel. Even something as simple as writing to STDOUT or opening a TCP connection is subject to restraint by capabilities.
According to the manual pages for capabilities:
"For the purpose of performing permission checks, traditional UNIX
implementations distinguish two categories of processes, privileged
processes and unprivileged processes. Privileged processes bypass all
kernel permission checks, while unprivileged processes are subject to
full permission checking based on the processes credentials."
A privileged process runs as root, its effective UID is 0. Unprivileged processes are those that run with a user ID other than 0. Privileged processes are not subject to permission checks by the Kernel while unprivileged processes are.
Unlike traditional file permissions capabilities are a bit more complex and numerous. Altogether there are 30 capabilities, each of which provides access to a different set of system calls.
As mentioned before a container shares a kernel with its host, as with other processes it will make permission calls to the same kernel. The capabilities that are assigned to a container restrict the types of calls it can make to the kernel. If the container's capabilities are not configured properly, or it is running as root and bypasses capability checks altogether then an attacker could can break container escalation in a myriad of ways depending on the capabilities assigned to the container process.
According to How To Hack Like A Ghost: Breaching The Cloud:
"Some of these capabilities can be leveraged to break namespace
isolation and reach other containers or even compromise the host by
sniffing packets routed to other containers, loading kernel modules
that execute code on the host, or mounting other containers file systems.
"
- Chapter 6 Fracture pg. 103
For example, the CAP_SETFCAP capability is used to "set arbitrary capabilities on a file". An attack caught in a container with this capability could add to the CAP_SYS_ADMIN capability to a copy of /bin/sh. CAP_SYS_ADMIN has been referred to as "the new root" because it allows for a ton of control of the host system. A container with this permission can mount file systems, modify control groups, perform administrative operations on device drivers and use the setns command which allows for the namespace of a process to be changed!
This is only scratching the surface, for more information on capabilities in general check out the Linux Man Pages. If you're interested in learning more about breaking container isolation you can check out this compendium of attack vectors by hacktricksxyz.
UNION FILE SYSTEM & CHROOT

If you've ever run a shell inside of a container and looked around you've probably noticed that it looks a hell of a lot like a regular Linux filesystem. If you traverse up to the / directory and run ls you'll find all of the usual suspects like /etc, /dev, /home, /bin and so on. The Union File System and chroot is responsible for creating the internal filesystem of the container.
The Union File System ie. UFS combines files and filesystems into a final coherent non-writable file system known as the image layer. Every time you spawn a container a copy of the image layer is mounted inside of the container process and made writable.
This provides enhanced efficiency. First, it ensures that building a container doesn't take up a ton of network bandwidth because it only has to pull the necessary files once when building an image. Because each layer of the image is non-writeable it can be used over and over again to spawn separate instances of the same container. Additionally, layers can be used across different container images.
Lastly reusing image layers improves storage utilization on the host system because it reuses a file over and over again rather than making copies of it. The Union File System is like Gorilla Glue, it takes files and whole filesystems and combines them by layering differences between variations of a file on top of one another.
In creating the file system of the container the UFS isn't the lone hero, it works in tandem with the chroot command. chroot is short for change root, and it changes the root directory, ie. the highest accessible directory a process can access. The UFS is primarily used for creating the containers file system while chroot is used to provide the actual isolation between a container and the host.
One of the benefits of a containerized environment is its speed and efficiency. So why does a container come with its own /bin, /proc and other sub root directories directories? Each of the subdirectories of / provides a distinct purpose in Linux. For commands run within the container it needs to have its own /bin directory, likewise, it needs its own /proc directory to manage processes.
Concluding Remarks
Containers are Linux processes, which are very distinct from virtual machines simply by the nature that they share a kernel with the host they run on. The essential building blocks of containers are namespaces, capabilities, cgroups, the union filesystem and chroot. Namespaces control what a container can see, cgroups control access to computational resources, capabilities control kernel system calls, the union filesystem builds the container filesystem and the chroot command isolates the container's filesystem from that of the host.
Securing containerized environments is similar to traditional ones in that the principle of least privilege should always be employed, and other attack vectors like those specified in the OWASP Top 10 still pose a threat. However, unlike traditional environments containers are built with somewhat unorthodox elements of the Linux system. If one wants to secure a containerized environment one needs to understand how it was built so that one can fortify the "walls" that ultimately bridge the container from the host system.